Moving Beyond Static Environment Variables: The Case for Dynamic, Typed Configuration

For over a decade, the 12-Factor App methodology has been the gold standard for modern application development. Its rule on configuration is simple: store it in the environment. This gave rise to the ubiquitous .env file and standard secrets managers, which have served us well. However, as distributed systems grow more complex and teams become fully remote, relying on static environment variables is starting to show its limitations.
The traditional approach to configuration is fundamentally static and untyped, leading to two major bottlenecks for engineering teams: brittle deployments and rigid runtime behavior. It’s time to rethink configuration not as a collection of flat text files, but as a dynamic, intelligent data layer.
The “String-Only” Trap: Why We Need Type-Safe Configuration
At the OS level, environment variables are exclusively strings. This means every time your application boots up, it has to parse these strings into the data types your code actually needs.
We’ve all been there: a developer accidentally sets a variable to ENABLE_FEATURE="True" instead of "true", or sets MAX_RETRIES="five" instead of 5. Because the environment variable is just a string, the application accepts it without complaint, only to throw a critical parsing error or behave unpredictably at runtime. This lack of a strict “contract” between the environment and the application code is a massive source of deployment anxiety.
By shifting to a type-safe configuration architecture, teams can enforce schema validation before the application even runs. When configuration supports native types like booleans, integers, and JSON objects, the application can validate its required settings during the build or startup phase.
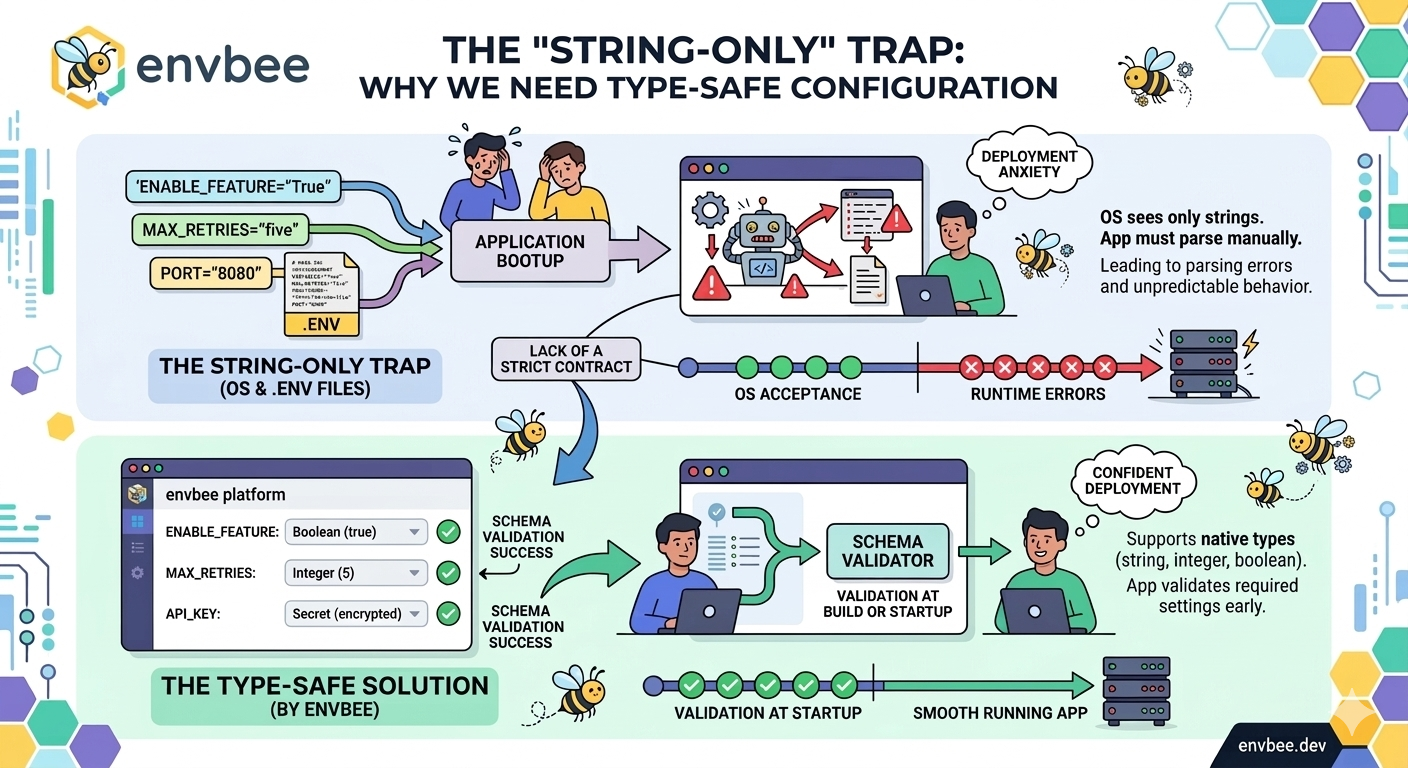
If a required integer is passed as a string of text, the system flags it immediately, completely eliminating a whole class of runtime crashes.
Decoupling Configuration from Deployment: Real-Time Behavior Control
The second major flaw of static environment variables is that they require an application restart—or worse, a full CI/CD deployment pipeline—to take effect.
Imagine your application is experiencing an unexpected traffic spike, and your database is struggling to keep up. You need to lower the MAX_DB_CONNECTIONS limit or enable a MAINTENANCE_MODE flag. With static environment variables, you have to update the variable, trigger a container rebuild, wait for the deployment to roll out, and hope the database survives the delay.
Modern architectures are moving toward dynamic configuration and hot-reloading. By utilizing a centralized configuration layer integrated via a lightweight SDK, applications can evaluate system parameters dynamically at runtime. This allows engineers to change system behavior instantly without altering the underlying infrastructure or redeploying code.
This unlocks powerful architectural patterns:
- Feature Toggling: Merging code to production but hiding it behind a dynamic boolean flag, allowing product managers to release features gradually without engineering bottlenecks.
- Incident Response: Adjusting rate limits, timeouts, or logging verbosity on the fly to diagnose and mitigate production issues in seconds, rather than minutes.
- Decentralized Control: Allowing QA to toggle backend logic on a staging environment instantly without needing DevOps to alter infrastructure code.
The Shift to a Dynamic Data Layer
Right now, the tech industry is pouring massive amounts of time and capital into AI tools to boost engineering velocity and improve software quality. But while AI can help us write code faster, fundamental operational bottlenecks—like messy configuration management and deployment drift—still quietly drain hours of productivity and cause entirely preventable outages. We cannot reach true engineering efficiency if we ignore the foundations; we have a wealth of architectural solutions available today that can solve these problems long before we need to resort to complex AI agents.
Treating configuration as a static afterthought is a missed opportunity. When we move beyond simple .env strings and embrace typed, dynamic configuration, we build more resilient systems. By ensuring that applications start with validated data and can adapt to changes dynamically, R&D teams can drastically reduce deployment failures, eliminate configuration drift, and respond to production events with unprecedented speed.